


By Christopher Kantos, Managing Director and Head of Quantitative Research at Alexandria Technology.
Given the changing industry landscape with the emergence of mega popular ChatGPT and other Generative AI, we have updated our previous work comparing NLP Approaches for Earnings Calls to include LLM’s (Large Language Models, ChatGPT specifically) to classify sentiment for earnings calls. First, we introduce ChatGPT, and review previous work looking at FinBERT, Loughran McDonald and Alexandria. We then analyse how each is constructed and trained and compare to see how the four approaches differ - or are similar - in analysing earnings calls for sentiment by looking at the correlation between them. Since we are using GPT-3.5 over the entire sample, we also look at the differences between GPT-3.5 and GPT-4 for the course of one year to see if there is material difference. Finally, we will construct a trading strategy using the S&P 500 and a subset of our database of 1.8 million earnings calls from the years 2010-2023 to compare the performance of each approach.
- Using Sentiment for earnings calls can generate alpha and lead to outperformance not explained by traditional risk and return factors.
- We find the low correlation of sentiment classification between ChatGPT and Alexandria at the individual section level, and the highest correlation between ChatGPT and FinBERT. Higher correlations are found at the aggregate security level but remain low.
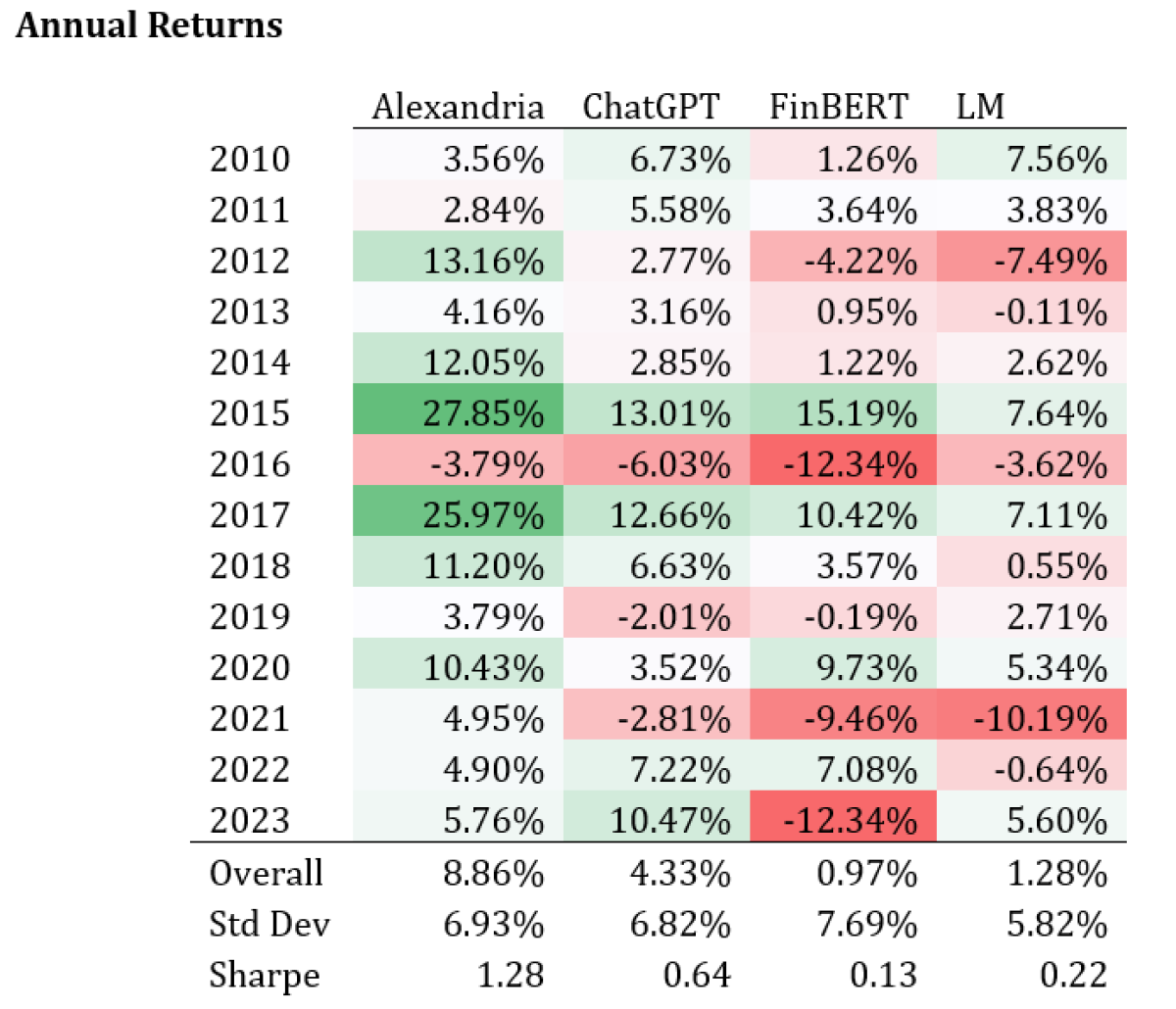
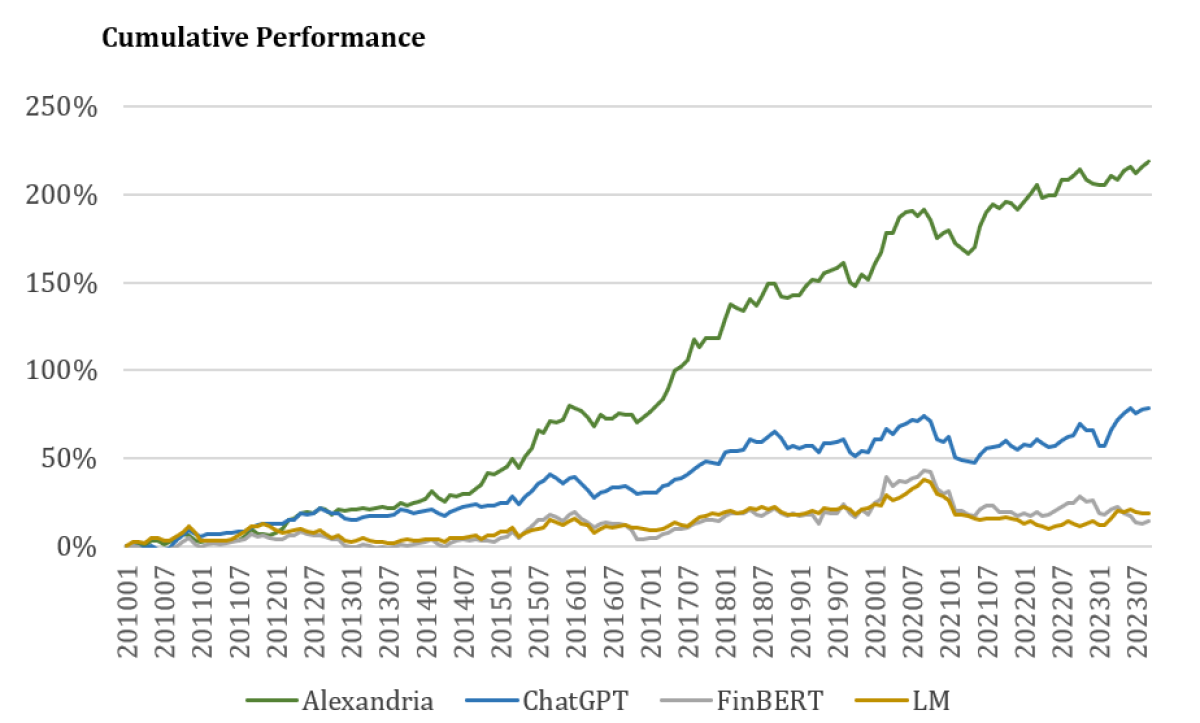
- Alexandria significantly outperforms ChatGPT and other approaches in our simulation over the period 2010-2023.
- Low correlation and large performance differences arise from the distinct language models, sentiment training and technology of each approach.
Background
ChatGPT (Generative Pre-trained Transformer) was developed as a large language model by OpenAI, first introduced in 2018 with GPT-1, and going through several iterations since culmination in its current version GPT-4 in 2023.
The goal of Large Language Models (LLM’s) in general is to process and generate human like text based on prompted input. Using transformer architecture, the model weighs relevance of different parts of the input to generate responses.
In our experiment, we look at GPT-3.5. GPT-3.5 uses unsupervised machine learning across the training dataset to create the language model. The model is trained mostly on text from the internet using common crawl which includes websites, books, news articles and other content. While not confirmed, it is generally accepted that the model is trained using data until late 2021 and prior including roughly 300 billion tokens in the training corpus.
The applications for LLM’s and ChatGPT are broad and evolving, and will no doubt change the way the world works. For the context of our simulation, we will use ChatGPT to analyse earnings call transcripts for sentiment as well as confidence in the sentiment given, explained below.
Prompting ChatGPT
The goal of the experiment will be for ChatGPT to classify the sentiment of corporate earnings calls for the constituents of the S&P 500 from 2010-2023. To achieve this, one critical element that we need to first explore is an appropriate prompt. If we are too general in prompting ChatGPT, this could lead to unfair responses, but also if our prompt is too narrow, it may limit ChatGPT’s ability to achieve a desired result. After consultation with financial market participants, we arrived at the following prompt to classify a section of an earnings call for sentiment:
"Act as a financial analyst reading a paragraph and predict if it would have a positive, negative or neutral impact on the stock price. Remove any non-financial text. Structure the output format exactly as {"sentiment" : "<sentiment of paragraph being one of [positive | negative | neutral]>", "sentiment_confidence": "<value between 0 and 1: your confidence in your prediction>"} and do not provide any additional descriptions"
Using the ChatGPT API, we are able to complete this prompt over 9 million times across over 76,000 S&P500 calls from 2010-2023. ChatGPT would provide results in the following format for each earnings call:
Earnings Call ID, Earnings Call Section ID, {Positive, Neutral, Negative}, Confidence
Across the entire sample, we find the following distribution of sentiment:
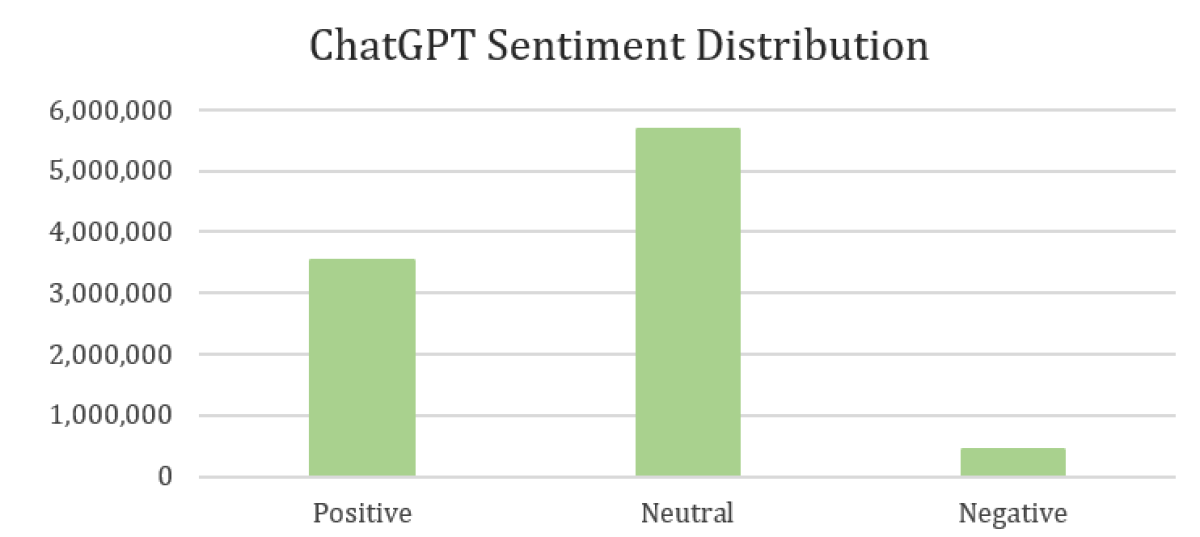
GPT-3.5 vs. GPT-4
During our analysis classifying earnings calls, OpenAI released the next version of the GPT family, GPT-4. In order to understand potential differences between GPT 3.5 and GPT 4, we classified a one-year period from October 2020 – November 2021 using GPT 4. We find the match rate between GPT-3.5 and GPT-4 to be 88.2%, with GPT-4 classifying slightly more Neutrals as either Positive or Negative.
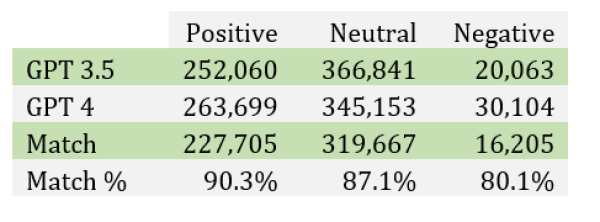
A large practical consideration in deciding to work with GPT 3.5 versus GPT 4.0 is the cost differential between both APIs. Classifying one year of earnings calls for sentiment with GPT-4 is the same cost as classifying 13.5 years with GPT-3.5. This appears to be a large step up in cost for a small difference in classification results.
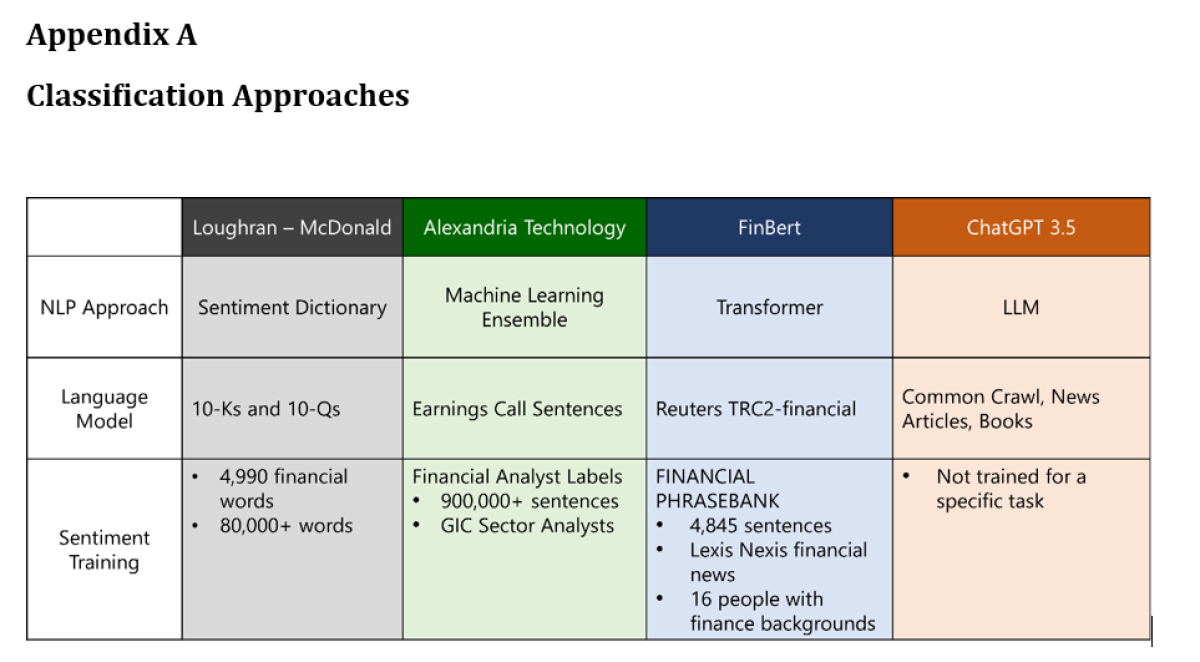
Loughran McDonald, FinBERT, and Alexandria Technology
Loughran McDonald
The Loughran McDonald (LM) lexicon, created in 2011 by Tim Loughran and Bill McDonald of Notre Dame, is a prominent financial lexicon approach in natural language processing (NLP). It addresses the limitations of the Harvard Dictionary, which often mislabels negative sentiments in financial contexts. The LM dictionary, developed using data from 10-Ks and 10-Qs between 1994 to 2008, consists of approximately 5,000 words from these financial documents and over 80,000 from the Harvard Dictionary, providing more accurate sentiment analysis in the financial sector.
FinBERT
FinBERT, developed in 2019, is a specialized adaptation of the BERT machine learning model, tailored for financial contexts. It leverages the Reuters TRC2-financial corpus, a financial-focused subset of the TRC2 dataset, for pre-training. This dataset comprises 46,143 documents with 29 million words and 400,000 sentences. For sentiment analysis, FinBERT uses the Financial Phrasebank, containing 4,845 sentences from the LexisNexis database, labelled by 16 financial experts. Additionally, the FiQA Sentiment dataset, consisting of 1,174 financial news headlines, further refines FinBERT's sentiment training capabilities.
Alexandria Technology
Developed in 2012, Alexandria Technology employs an ensemble of machine learning techniques originally designed for understanding the human genome and adapted for the institutional investment industry. Alexandria’s earnings call language model is trained on millions of earnings transcripts provided by FactSet. Sentiment classification incorporates sentiment training from over 900,000 unique sentence labels provided by financial analysts reviewing earnings call transcripts. Each of Alexandria’s models is document specific and domain expert trained.
For comparison of the 4 approaches, see Appendix A. For examples of classification differences see Appendix B.
Correlation Among the Approaches
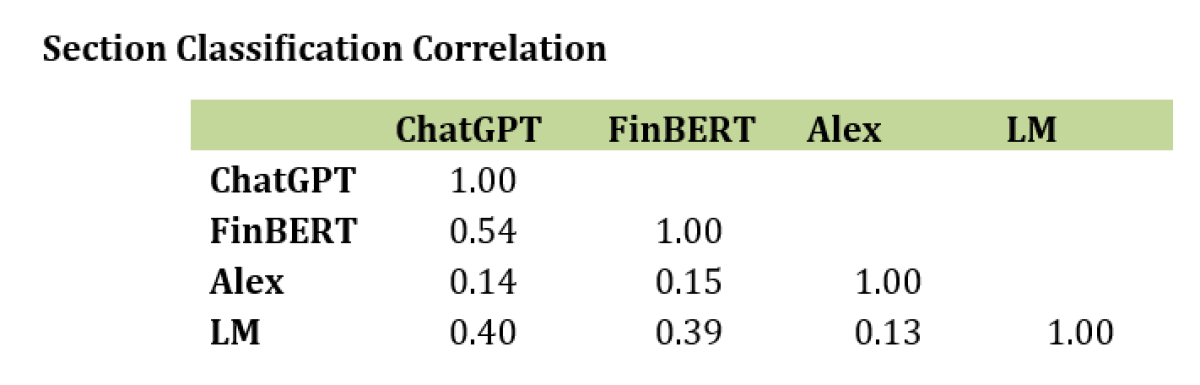
In addition to now having sentiment labels for ChatGPT, we repeat this process for Loughran McDonald, FinBERT, and Alexandria at the individual section level for each earnings call. Across the entire sample, we find the highest correlation between ChatGPT and FinBERT at 0.54, followed by ChatGPT and Loughran McDonald at 0.40 and FinBERT and Loughran McDonald at 0.39. The lowest correlation was between Alexandria and Loughran McDonald, FinBERT, and ChatGPT at 0.13, 0.14, and 0.15 respectively. Below is the correlation matrix across the sample. In Appendix B, we show several examples of text, and based on the training of the language model and the ability to understand context, the approaches can differ in their sentiment classification.
Simulation
For our simulation, we run a monthly long-short strategy where we are long the most positive stocks and short the least positive (most negative) stocks based on earnings call sentiment classifications.
Using the S&P 500 as our universe, we calculate sentiment scores at 09:00 ET on the last business day of each month. We then assume we enter positions at 16:00 ET on the last business day of the month, giving us the entire day to fill all orders.
Given earnings calls occur only one month per quarter, we use a rolling three (3) month aggregation window to compute sentiment scores. For example, for trading on November 30, 2023, we include any calls during the period of September 1, 2023 to November 30, 2023. This allows us to have a score for all of the S&P 500 constituents each month.
For the sentiment computation, we first separate the earnings calls into two sections, the Management Discussion (MD) and the Question and Answer (QA). For each individual component of MD and QA, we create a section sentiment by calculating the ratio of positive to negative statements made in the section. Neutral statements are ignored.
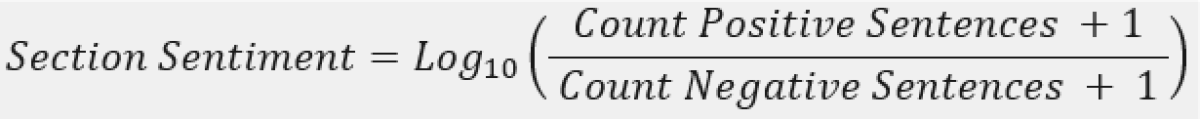
After we compute each section sentiment, we then take a simple average of each section sentiment to compute a final Net Sentiment for each company. Here, we are looking for agreement or divergence between the MD and QA. If the MD and QA are both positive, a company will rank highly and if the MD and QA are both negative, a company will rank poorly. If there is disagreement, a company will have a more neutral score.
Based on the sentiment scores each month, we percentile rank the stocks in the universe and split the stocks into Quintiles of 100 stocks. Stocks within each quintile are equal weighted. We assume we go long Quintile 1 and Short Quintile 5. Quintiles 2-4 will be ignored.
The simulation period runs from January 2010 through September 2023.
Over the course of the sample period, portfolios created from the Alexandria classifier have the highest performance, with an overall Sharpe ratio of 1.28, followed by ChatGPT with 0.64, Loughran McDonald 0.22 and finally FinBERT at 0.13. Annual and Cumulative results shown below.
Conclusion
While Generative AI has broad applications[1] that will change the workflows for many industries, there is still a case to be made for domain specific NLP. ChatGPT and other LLM’s are models that have been trained on large amounts of various domains, making them indispensable for saving time and increasing efficiency. Alexandria has taken an approach to NLP that is domain specific - each language and sentiment classifier is trained wholly using the documents we are analysing, whether that be News, Social Media, or Earnings Calls. In addition, we use labels that are derived from domain expert, resulting in much more accurate and reliable classification.
In previous research, we have shown that using our 900,000 expert labels to retrain FinBERT can produces 5x performance increases over the standard FinBERT model. High quality inputs and media specific models appear to outperform broader, generalised models.
As a next step to continue this research, we will explore training LLM’s using our expert labels to classify the sentiment of earnings calls. In doing so, we may be able to increase the accuracy and precision of the classification compared to what is currently available with existing models, making the analysis more reliable and contextually relevant as well.
[1] ChatGPT was not responsible for the generation of any content of this paper, grammatical errors and typos belong to the author alone.
Appendix B
Classification Examples

About the Author:
Christopher Kantos is a Managing Director and Head of Quantitative Research at Alexandria Technology.

He is responsible for exploring ways natural Language Processing and Machine Learning can be applied in the financial domain. Prior to Alexandria, Chris spent over 15 years in financial risk at Northfield Information Services as a Senior Quantitative Risk Analyst and Director for the EMEA region. He is a frequent contributor and presenter of quantitative research topics globally, with publications in peer-reviewed journals and other professional venues. Chris graduated magna cum laude in Computer Engineering from Tufts University, and a Masters from Imperial College London.