Chronicles of an Allocator: Alternative Data
This month’s newsletter covers the exploding world of alternative data, and the foreword is authored by Keith Black, PhD, CFA, CAIA, FDP. Keith was recently appointed Managing Director and Program Director at the Financial Data Professional (FDP) Institute, the organization responsible for the FDP Charter Program.
The growth of and use case for alternative data has grown dramatically over the last decade, which is further explored by Keith below:
“Your future is whatever you make it, so make it a good one.”
– Doctor Emmett Brown, Back to the Future
I feel old when I think of movies like “Back to the Future.” The 1985 movie flashed back to 1955 and traveled forward in time to October 21, 2015. That is, 2015 is as far from 1985 as 1985 is far from 1955. As we think about how the world changed from 1955 to 1985 to 2015, we can really envision how the world, and our careers, will unfold over the next 30 years.
It was high school, in 1985, where I learned to program computers using storage devices that predate the floppy disk, such as punch cards and cassette tapes. In my undergraduate computer science studies, I learned languages such as Assembly, Pascal, and Fortran. At this time, you had to direct the computer every step of the way, sometimes loading data in and out of memory due to technical limitations.
Ten years later, I worked as a quantitative equity analyst. I was able to use a backtesting engine to test combinations of structured data to predict how stock prices would react to measures of value, growth, earnings momentum, and price momentum. The data was highly structured, where we could load tables of numerical values sorted by tickers. Data came primarily from each company’s quarterly income statement and balance sheet reports, supplemented with price data from stock exchanges and analyst estimates from specialized database providers.
At the time, the frontier of data analysis was studying the earnings estimates of sell-side analysts and comparing those estimates to the earnings reported by public companies each quarter, the difference being referred to as an “earnings surprise.” The true vanguard of quants was sorting through the estimates of individual sell side analysts to put more weight on the estimates of the most accurate analysts or the ones who revised their estimate the earliest or most often.
“Roads? Where we’re going, we don’t need roads.”
– Doctor Emmett Brown, Back to the Future
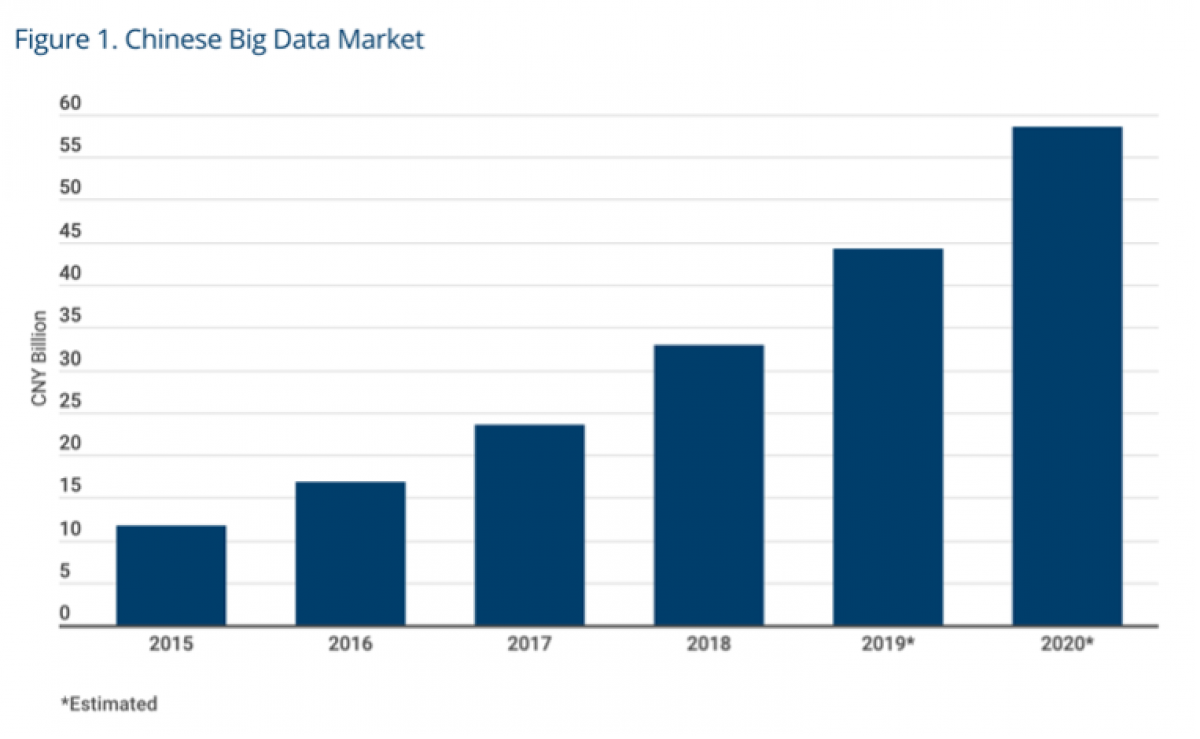
By 2015, more data (28 zettabytes) had been created in just two years than in the entire recorded history of mankind. The Statista estimate for 2021 alone is 79 zettabytes which could double again by 2025. Where does all this data come from? You likely already know that services that are free to you (e.g., Baidu, Google, Facebook, or WeChat), are monetizing your data. Ideally, after removing all personally identifiable information (PII), hedge funds are reading your email and adding up the transactions on your credit card receipts. They follow the geolocation of your cell phone and can use satellites to track global shipping containers. Through natural language processing, your social media posts can be mined for the positive or negative sentiment relative to the macro economy or toward individual stocks.
This alternative data, however, is messy and unstructured, requiring a lot of work to tame it. However, the most value may be found in the untamed and raw data. And there is value in this data! In the three years ending May 2020, hedge funds employing artificial intelligence techniques outperformed the global hedge fund industry by over 700 basis points per year. Where do these profits come from? Nowcasting. We no longer need to wait for the quarterly revenue or profit reports of companies, as we already have a good idea of those numbers by aggregating drone or satellite photos of shopping center parking lots or the receipts of the credit card transactions we read. That is, nothing is a surprise anymore if you have the right data and the right analysts.
Fortunately, you don’t need to program in assembly language and store data on punch cards. The generosity of the open-source R and Python communities is so amazing that you can now build a machine learning model using less than ten lines of code. Those lines of code simply point to the data set and call a routine such as random forest using the parameters you supply.
“If you put your mind to it, you can accomplish anything!”
– Doctor Emmett Brown, Back to the Future
There’s so much innovation happening today already. Are you prepared for what’s to come in the next 30 years?
Keith Black, PhD, CFA, CAIA, FDP
Managing Director/Program Director, FDP Institute
----
Welcome to the October edition of Chronicles of an Allocator, where we’ve curated content on alternative data that we hope helps aid your decision process. Of course, if you’re interested in upgrading your knowledge on this topic, I would encourage you to register for an upcoming webinar, co-hosted by FDP Institute and CAIA Association, Practical Machine Learning in Asset Management: Manager Selection and Valuing the Secondary Sale of Private Assets. Even better, consider becoming a candidate in the Financial Data Professional (FDP) Program.